1.12 Cumulative Distribution Function, Kaplan-Meier, and Cumulative Incidence Function Figures
Regardless of the study type performed, there will inevitably be loss of study members over time. While the QRP can perform statistical techniques to account for this loss-to-follow-up, users may desire to visualize the impact of censoring. Depending on the study design, the QRP reporting tool provides two types of figures to fit this purpose. In the context of these visualizations, “censoring” refers to any reason that leads to the end of observed time.
For studies where exposed and unexposed members are followed over time for the occurrence of a user-specified outcome—i.e., Exposures and Follow-Up Time [Type 2] and Medical Product Switching Patterns [Type 6]—the reporting tool outputs Kaplan-Meier (K-M) curves. The QRP reporting tool plots follow-up time in days on the x-axis and the cumulative conditional probability that the outcome of interest has not occurred on the y-axis. This probability is calculated using the K-M estimator of the complement of the cumulative distribution function—i.e., 1-CDF—as described in the “Calculation” section below. Because the cumulative probability is conditioned on all reasons for censoring and presumably not all study members experience the outcome of interest, the K-M estimator of the complementary cumulative probability will start at 1 when the study begins and end somewhere above 0 at the end of the study.
For studies where no outcome is specified formally, users can still visualize the cumulative probability that a given censoring reason has not occurred over time. In contrast to the K-M curves described above, these figures plot unconditional probability; in other words, the probability that a study member has not experienced the censoring reason of interest at each point in time among members who do experience that censoring reason. Because of this, these figures (described as “1-CDF” in the table below) display a cumulative probability of 1 at time 0 and cumulative probability of 0 at the end of the study.
For Type 6 switching analyses, another censoring criterion may occur as a competing risk—e.g., treatment cessation. Cumulative incidence functions display figures for time to first or second switch accounting for a user-specified competing risk. In the presence of a competing risk, Kaplan-Meier curves will overestimate the cumulative incidence of switching.
Using parameters in the QRP Report Figure File, users can specify which figures they would like output as well as which censoring reasons to display and the way in which to display them on each figure. Additionally, for inferential analyses, users can specify whether to stratify figures by data partner using the QRP Report Create Report File. The CENSORDISPLAY parameter can be used to specify the censoring reason to be used as a competing risk.
The user can specify in the QRP Report Groups File which cohort groups should be displayed for Type 1, descriptive Type 2, and Type 5 analyses, as well as which analysis groups should be included for Type 6 switching analyses.
For inferential Type 2 analyses using propensity scores (PS), the user can output unadjusted K-M figures, as relevant for the chosen analysis type. The user does not have an option of which analysis groups to include. If unadjusted K-M figures are requested, they will automatically be output for each subgroup analysis category, if specified.
The K-M figures for propensity score analyses will automatically include 95% confidence intervals, except for conditional PS matched analyses when the population is weighted or both unweighted and weighted.
| Inferential Analysis Type | K-M figures available |
|---|---|
| 1:n fixed-ratio PS-matched analysis |
|
| 1:n variable-ratio PS-matched analysis |
|
| Unweighted PS stratified analysis |
|
| PS stratum weighted analysis |
|
| Inverse probability of treatment weighted (IPTW) analysis |
|
| Covariate stratified analysis |
|
Figure 1.6 shows a complete list of available figures and their properties for each type of analysis.24
See below for a complete list of available figures and their properties for each type of analysis.
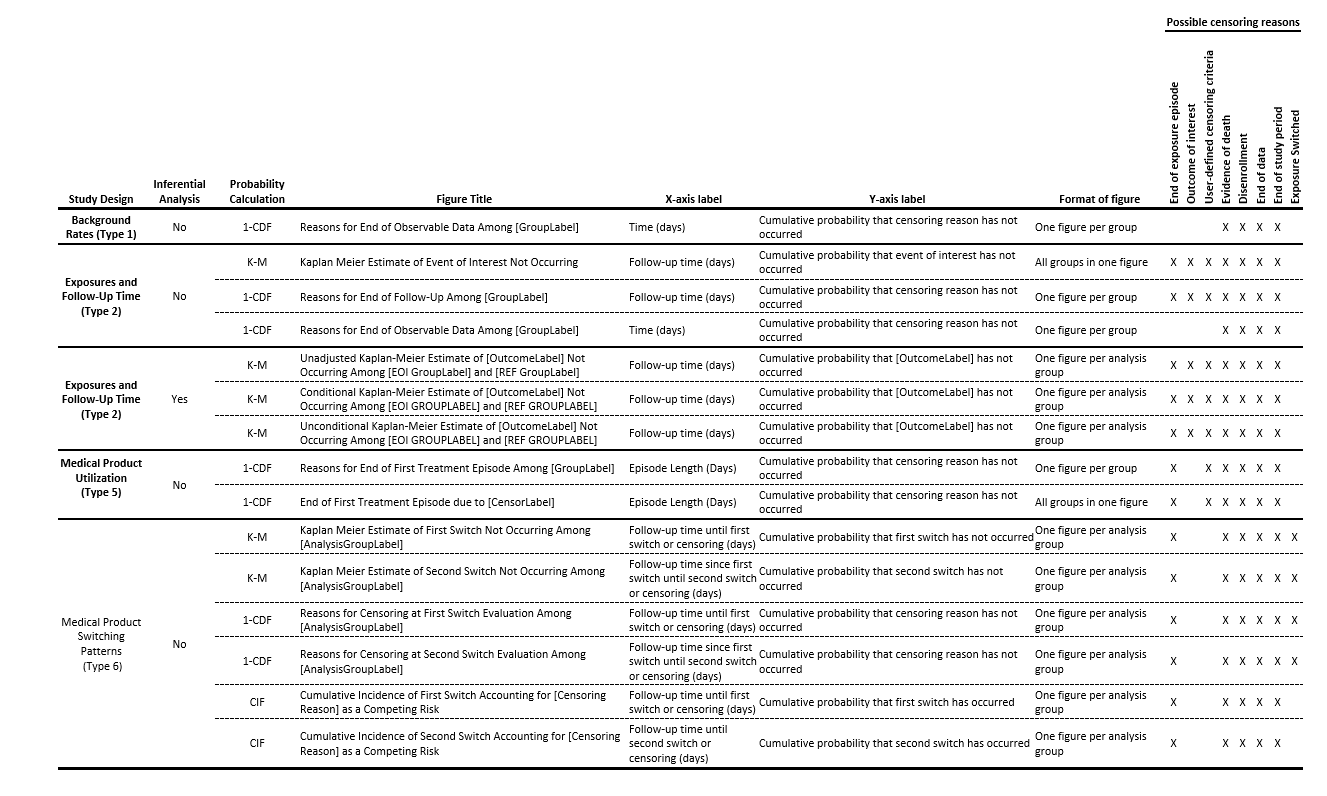
Figure 1.6: Figure Properties by Study Design and Analysis Type
1.12.1 User Options
For each censoring reason, the user can specify a custom label in the QRP Report Label File. However, only one custom label is allowed per report. If no custom labels are specified, these default censoring labels will be used:
- End of Exposure Episode
- Occurrence of Outcome of Interest
- Occurrence of User-Defined Censoring Criteria
- Evidence of Death
- Disenrollment
- End of Data
- End of Study Period
- First Switch
- Second Switch
Values for [OutcomeLabel] and [GroupLabel], which are part of the x-axis labels and the figure titles can be specified by the user in QRP Report Label File.
For variable-ratio PS-matched analyses, the user has the option of displaying curves for weighted and/or unweighted reference cohorts in the conditional K-M figure using the appropriate parameter in the QRP Report (L2 Comparison File)(#file3040-l2comparison). In order to output the weighted cohort in the figure, the user must request that individual-level data be returned in qrp.QRP_Parameters.
The user must specify whether to include the weighted comparison group, the unweighted real population, or both in this figure.
1.12.1.1 Tick-Marks
The user can specify the minimum value, the maximum value and the interval between tick marks for both the X and Y axes using parameters in QRP Report Figure File. The user may instead choose to use the program defaults for these. For the y-axis, the minimum value default is zero, the maximum value default is 1, and the tick marks are at every 0.2 between 0 and 1. The x-axis maximum default is the maximum number of days in the data. For a non-Type 6 figure, the x-axis minimum default is 0. For a Type 6 figure, the x-axis minimum default is 0, unless a negative time to switch is included, in which case it is the minimum data value. The user can specify whether to include negative time to switch in the qrp_report.GroupsFile.
If the user does not specify an interval between tick marks for the x-axis and the length of the x-axis is >120 days, then ticks will be placed at a multiple of 30—.e., every 60 days or every 90 days, etc., depending on the number of days on the axis. If the user does not specify an interval between tick marks for the x-axis and the length of the x-axis is between 10 and 120 days, then tick marks will be placed at a multiple of 5. The goal of the tick mark algorithm is to print six tick marks on the axis.
1.12.1.2 Members Remaining in Study Table
Users have the option to output a table below each figure that includes the number of episodes remaining in the analysis at each time point—e.g., on day 10 if there are 10 episodes and they are all censored on that day, the number at-risk is 10. In order to output this table, users must request it in qrp_report.FigureFile. The time points displayed in the table columns correspond to the tick marks on the x-axis of the associated figure.
1.12.2 Calculations
Suppose \(X\) is a random variable. Then, the cumulative distribution function, \(F(x)\), is defined as the probability that \(X\) takes a value less than or equal to \(x\), as shown in Equation (1.19), where \(x_{n}\) is the largest value of \(X\) that is less than or equal to \(x\).
Equation (1.19): Cumulative Distribution Function
\[\begin{equation} F\left(x\right)=Pr\left(X\le x\right)=\sum_{k=1}^{n}Pr\left(X=x_k\right) \tag{1.19} \end{equation}\]In studies performed using QRP, the random variable of interest is generally time, \(t\), and understanding how long a study member persists in the study without the event of interest. This function is known as the reliability function, \(G(t)\), and is the complement of the cumulative distribution function, as shown in Equation (1.20). Because all individuals eventually experience censoring (the event of interest in the “1-CDF” figures generated by the QRP reporting tool), at any point in time the reliability function can be approximated as the product estimator of 1 minus the number of individuals experiencing the event of interest at that time, \(e_{i}\), divided by the number of individuals yet to experience the event.
Equation (1.20): Reliability Function of Distribution
\[\begin{equation} G\left(t\right)=1-F\left(t\right)=Pr\left(T>t\right)~\prod_{i:t_i\le t}{1-\frac{e_i}{n_i}} \tag{1.20} \end{equation}\]Because all reasons for censoring are known, the QRP reporting tool uses the reliability function to estimate the cumulative probability that a study member has remained in the study until time \(t_{i}\).
When users perform a study with follow-up and at-risk time in the presence of censoring (i.e. descriptive or inferential unweighted Type 2 and descriptive Type 6) and would like to visualize the cumulative probability that the outcome of interest has not occurred conditioned on all reasons for censoring, the QRP reporting tool uses the standard Kaplan-Meier estimator, calculated as shown in Equation (1.21) where at each time point, \(t_{i}\), the cumulative probability that the outcome has not occurred is the complement of the number of individuals experiencing the event at ti divided by the number of individuals remaining at-risk for the outcome of interest at that time (\(r_{i}\)). At the final time point where \(t_{i} \le t\), the cumulative probability that the outcome has not occurred will always be \(>0\) assuming censoring has occurred. As can be seen in Equations (1.20) and (1.21), the main difference between the “1-CDF” and “K-M” curves output by the QRP reporting tool is whether individuals who are censored are considered as having the event of interest—i.e. in the numerator, \(e_{i}\)—or remaining in the study at-risk for the event—i.e., in the denominator, \(n_{i}\).
Equation (1.21): Standard Kaplan-Meier Estimator
\[\begin{equation} \hat{S}\left(t\right)=\prod_{i:t_i\le t}\left[1-\frac{e_i}{n_i}\right] \tag{1.21} \end{equation}\]where
- \(S(t)\) is the K-M estimator at time point \(t\)
- \(\hat{S}(t)\) is the estimate at time point \(t\)—i.e., the actual observed value
- \(e_{i}\) is the number of individuals experiencing the outcome of interest at time \(i\)
- \(n_{i}\) is the number of individuals remaining at-risk for the outcome of interest at time \(i\)
The 95% confidence interval (CI) for the standard K-M estimator is calculated using the standard error outlined in Equation (1.22) below:
Equation (1.22): Standard Error for Kaplan-Meier Survival Estimate at Time \(t\)
\[\begin{equation} SE\left(\hat{S}\left(t\right)\right)=\hat{S}\left(t\right)*\sqrt{\sum_{t_{i}\le t}\frac{e_{i}}{n_{i}\left(n_{i}-e_{i}\right)}} \tag{1.22} \end{equation}\]where
- \(\hat{S}\left(t\right)\) is the estimate at time point \(t\) (i.e., the actual observed value)
- \(e_{i}\) is the number of individuals experiencing the outcome of interest at time \(i\)
- \(n_{i}\) is the number of individuals remaining at-risk for the outcome of interest at time \(i\)
To avoid 95% CIs that fall outside the (0,1) boundaries of \(S(t)\), the calculation of the 95% CI is log-log transformed as shown in Equation (1.23) below:
Equation (1.23): Log-log Transformed 95% CI for Kaplan-Meier Survival Estimate
\[\begin{equation} \hat{S}\left(t\right)^{exp\left(\frac{\pm 1.96*SE\left(\hat{S}\left(t\right)\right)}{ln\hat{S}\left(t\right)}\right)} \tag{1.23} \end{equation}\]For inferential analysis using variable-ratio propensity score matching—i.e., \(1:m\) matched data, where \(m\) varies—Kaplan-Meier estimates among the unexposed are adjusted for the number of times a patient is matched in the analysis as shown in Equation (1.24). Each reference patient is weighted by the reciprocal number of unexposed individuals in the matched set—i.e., \(w_{j} = \frac{1}{m_{j}}\) where \(m_{j}\) is the number of unexposed individuals in a given stratum. These weights are applied to outcome and patient counts, after which the usual K-M estimator is applied.
Equation (1.24): Weighted Kaplan-Meier Estimator for Variable Ratio Matching
\[\begin{equation} {\hat{S}}^w\left(t\right)=\prod_{i:t_i\le t}\left[1-\frac{\sum_{j=1}^{k}{w_j{e_j}_i}}{\sum_{j=1}^{k}{w_j{n_j}_i}}\right] \tag{1.24} \end{equation}\]where
- \(j=1, 2, \dots, k\) is the index for strata
- \(S_{w}(t)\) is the K-M estimator at time point \(t\)
- \(w_{j}\) is the weight for each stratum
- \(e_{ji}\) is the number of individuals in each stratum experiencing the outcome of interest at time \(i\)
- \(n_{ji}\) is the number of individuals in each stratum remaining at-risk for the outcome of interest at time \(i\)
As shown in Galimberti 20029, his weighted Kaplan-Meier estimator converges to the standard K-M estimator as the number of strata goes to infinity. This can be seen in the case of a \(1:1\) analysis, where each individual has their own stratum. Because of this, the weighted K-M estimator is only used to generate the K-M curve for the comparator group, since the standard K-M estimator would work for the treatment group under the \(1:m\) matching ratio. Methods to estimate the 95% CI for this weighted survival curve are not available.
Equation (1.25): Cumulative Incidence Function
\[\begin{equation} \sum_{j=1}^{k}{\left(\frac{d_j}{n_j}\right)\ast S\left(t_{j-1}\right)} \tag{1.25} \end{equation}\]
where
- \(j=1,2,\dots,k\), is the index for strata
- \(d_{j}\) is the number of outcomes of interest at time \(t_{j}\)
- \(n_{j}\) is the number of patients at risk before immediately before event time \(t_{j}\)
- S(tj-1) is the Kaplan Meier survival estimate for not having had either the outcome of interest or the competing risk at in the interval between \(t_{j}\) and the prior time \(t_{j-1}\)
As shown in Satagopan et al. 200410, this approach to calculating cumulative incidence appropriately accounts for a competing risk. In the presence of competing risks, the standard K-M estimator would overstate cumulative incidence.
1.12.2.1 K-M Survival Estimate Calculations for IPTW and PS Stratum Weighted Analyses
For IPTW or PS stratum weighted analyses, the K-M survival estimate is calculated using information about the weights in each risk set, available in the [RUNID]_marginalweights_[PERIODID].sas7bdat file.
| SumEC | SumC | SumE | SumUnE | SumSquareEC | SumSquareUnEC | SumSquareE | SumSquareUnE | FollowUpTime |
|---|---|---|---|---|---|---|---|---|
| Risk set 1 | Risk set 1 | Risk set 1 | Risk set 1 | Risk set 1 | Risk set 1 | Risk set 1 | Risk set 1 | Risk set 1 |
| Risk set 2 | Risk set 2 | Risk set 2 | Risk set 2 | Risk set 2 | Risk set 2 | Risk set 2 | Risk set 2 | Risk set 2 |
| Risk set 3 | Risk set 3 | Risk set 3 | Risk set 3 | Risk set 3 | Risk set 3 | Risk set 3 | Risk set 3 | Risk set 3 |
| … | … | … | … | … | … | … | … | … |
First, site-specific K-M curves and 95% CI are generated for both the exposed and reference groups according to the following calculations.
For each site \(k\), let \(t_j\), \(j=1,\ldots,D(k)\) denote the ordered, distinct event times.
1.12.2.1.1 Generating the K-M curve of the exposed group
Step 0: Re-organize the shared risk set tables such that the \(j^{th}\) row represents the \(j^{th}\) ranked event times. This can be done by sorting the tables with columns sumSquareE and sumSquareUnE both decreasing.
Step 1: Calculate \(\text{RatioE}=\frac{\text{SumEC}}{\text{SumE}}\), a vector of ratios.
Step 2: Plot the survival probability \({\hat{S}}_{k,1}\left(t\right)\) for the exposed group over time \(t\), where:
\[ {\hat{S}}_{k,1}\left(t\right)=\begin{cases}1, & \text{ if }t<t1 \\ \underset{j:tj≤t1}{\text{cumprod}\left(1-RatioE\right)}, &\text{ if }t≥t1 \end{cases} \]
where \(\underset{{j:t}_j\le t}{\text{cumprod}}\left(1-RatioE\right)\) is a cumulative product operator for the first \(j\) components of vector \(\left(1-RatioE\right)\) such that \(t_j\le\ t\) and \(t_{j+1}>t\). For example, suppose \(1-RatioE=(0.9,\ 0.8,\ 0.7,\ 0.6,\ 0.5)\) for five risk sets at event times \(1\), \(2\), \(3\), \(4\), and \(5\). Then, for \(t=2.7,\ \underset{{j:t}_j\le t}{\text{cumprod}}{\left(1-RatioE\right)}=0.9\times\ 0.8=0.72\).
1.12.2.1.2 Generating the K-M curve of the reference group
Step 3: Calculate \(\text{RatioUnE}=\frac{\left(\text{SumC}-\text{SumEC}\right)}{\text{SumUnE}}\), a vector of ratios
Step 4: Plot the survival probability \({\hat{S}}_{k,0}\left(t\right)\) for the reference group over time \(t\), where \[ {\hat{S}}_{k,0}\left(t\right)=\begin{cases}1,& \text{if } t<t1 \\ \underset{j:t_j \leq t}{\text{cumprod}}\left(1-\text{RatioUnE}\right), & \text{if }t≥t1 \end{cases} \]where \(\underset{j:tj≤t}{\text{cumprod}\left(1-\text{RatioUnE}\right)}\) is a cumulative product operator for the first \(j\) components of vector \(\left(1-RatioUnE\right)\) such that \(t_j\le\ t\) and \(t_{j+1}>t\). For example, suppose \(1-RatioUnE=(0.9,\ 0.8,\ 0.7,\ 0.6,\ 0.5)\) for five risk sets at event times \(1\), \(2\), \(3\), \(4\), and \(5\). Then, for \(t=2.7,\ \underset{j:tj≤t}{\text{cumprod}\left(1-\text{RatioUnE}\right)}=0.9\times\ 0.8=0.72\).
1.12.2.1.3 Variance estimation and bounded 95% CI for K-M curve of the exposed group
Step 5: Calculate the vector \(VE=\frac{RatioE}{(1-RatioE)\times{(SumE)}^2\ /\ SumSquareE}\)
Step 6a: Calculate the variance estimator of the survival probability \({\hat{S}}_{k,1}\left(t\right)\) for the exposed group over time \(t\): \[ \widehat{var}\left({\hat{S}}_{k,1}\left(t\right)\right)=\left({\hat{S}}_{k,1}\left(t\right)\right)^2\underset{{j:t}_j \le t}{\text{cumsum}}\left(VE\right) \] where \(\underset{{j:t}_j \le t}{\text{cumsum}}\left(VE\right)\) is a cumulative summation operator for the first \(j\) components of vector \(VE\) such that \(t_j\le\ t\) and \(t_{j+1}>t\). For example, suppose \(VE=(0.1,\ 0.05,\ 0.2,\ 0.3,\ 0.02)\) for five risk sets at event times \(1\), \(2\), \(3\), \(4\), and \(5\). Then, for \(t=2.7,\ \underset{{j:t}_j \le t}{\text{cumsum}}\left(VE\right)=0.1+0.05=0.15\).
- To make sure the CI is bounded between 0 and 1, we use complementary log-log transformation and delta method—i.e., obtain 95% CI for the transformed estimate and then transform the results back to the original scale. Specifically, calculate: \[ cVE(t)=\frac{1}{\left[log\left\{\hat{S}_{k,1}t\right\}\right]^2}\underset{j:tj \leq t}{\text{cumsum}\left(VE\right)} \]. Then the bounded 95% CI for \({\hat{S}}_{k,1}\left(t\right)\) is: \[ S_{k,1}t^{exp\left[1.96\sqrt{cVE(t)} \right]}\\ \text{to} \\ S_{k,1}t^{exp\left[-1.96\sqrt{cVE(t)}\right]} \]
1.12.2.1.4 Variance estimation and bounded 95% CI for K-M curve of the reference group
Step 7: Calculate the vector \(VUnE=\frac{RatioUnE}{(1-RatioUnE)\times{(SumUnE)}^2\ /\ SumSquareUnE}\)
Step 8a: Calculate the variance estimator of the survival probability \({\hat{S}}_{k,0}\left(t\right)\) for the unexposed group over time \(t\):
\[ \widehat{var}\left(\hat{S}_{k,0}\left(t\right)\right)=\left(\hat{S}_{k,0}\left(t\right)\right)^2 \underset{j:t_j \le t}{\text{cumsum}}\left(\text{VUnE}\right) \] where \(\underset{j:t_j \le t}{\text{cumsum}}\left(\text{VUnE}\right)\) is a cumulative summation operator for the first \(j\) components of vector VUnE such that \(t_j\le t\) and \(t_{j+1}>t\). For example, suppose \(VUnE=(0.1,\ 0.05,\ 0.2,\ 0.3,\ 0.02)\) for five risk sets at event times \(1\), \(2\), \(3\), \(4\), and \(5\). Then, for \(t=2.7, \underset{j:t_j \le t}{\text{cumsum}}\left(\text{VUnE}\right)=0.1+0.05=0.15\).
Step 8b: To make sure the CI is bounded between 0 and 1, we use complementary log-log transformation and delta method—i.e., obtain 95% CI for the transformed estimate and then transform the results back to the original scale. Specifically, calculate:
\[ cVUnE(t)=\frac{1}{\left[\log\left\{{\hat{S}_{k,0}\left(t\right)}\right\}\right]^2}\underset{j:t_{j} \leq t}{\text{cumsum}}\left(\text{VUnE}\right) \]
Then the bounded 95% CI for \({\hat{S}}_{k,0}\left(t\right)\) is:
\[ S_{k,1}t^{exp\left[1.96\sqrt{cVUnE(t)} \right]}\\ \text{to} \\ S_{k,1}t^{exp\left[-1.96\sqrt{cVUnE(t)}\right]} \]
Once site-specific curves for both exposure groups have been calculated, the aggregated curve for each exposure group is calculated according to the following:
- Obtain an ordered list of event times for all sites. For example, suppose site 1’s risk set table is:
| SumEC | SumC | SumE | SumUnE | SumSquareEC | SumSquareUnEC | SumSquareE | SumSquareUnE | FollowUpTime |
|---|---|---|---|---|---|---|---|---|
| 4 | 9 | 20 | 23 | 29 | 30 | 40 | 53 | 1 |
| 2 | 5 | 10 | 15 | 20 | 25 | 30 | 45 | 6 |
| 1 | 3 | 8 | 14 | 17 | 22 | 25 | 40 | 12 |
and site 2’s risk set table is:
| SumEC | SumC | SumE | SumUnE | SumSquareEC | SumSquareUnEC | SumSquareE | SumSquareUnE | FollowUpTime |
|---|---|---|---|---|---|---|---|---|
| 5 | 8 | 21 | 22 | 30 | 31 | 36 | 51 | 2 |
| 3 | 6 | 12 | 17 | 21 | 26 | 33 | 49 | 6 |
| 1 | 2 | 7 | 12 | 15 | 20 | 24 | 29 | 10 |
Then, the list of event times is {1, 2, 6, 10, 12}.
- Combine site-specific risk set tables into one table sorted by the ordered list of event times. It is possible to have multiple rows with the same event time. In our example, we obtain:
| SumEC | SumC | SumE | SumUnE | SumSquareEC | SumSquareUnEC | SumSquareE | SumSquareUnE | FollowUpTime |
|---|---|---|---|---|---|---|---|---|
| 4 | 9 | 20 | 23 | 29 | 30 | 40 | 53 | 1 |
| 5 | 8 | 21 | 22 | 30 | 31 | 36 | 51 | 2 |
| 2 | 5 | 10 | 15 | 20 | 25 | 30 | 45 | 6 |
| 3 | 6 | 12 | 17 | 21 | 26 | 33 | 49 | 6 |
| 1 | 2 | 7 | 12 | 15 | 20 | 24 | 29 | 10 |
| 1 | 3 | 8 | 14 | 17 | 22 | 25 | 40 | 12 |
- Combine the rows with the same event time by adding up each of the 8 columns of summary-level info on weights. In our example, we have:
| SumEC | SumC | SumE | SumUnE | SumSquareEC | SumSquareUnEC | SumSquareE | SumSquareUnE | FollowUpTime |
|---|---|---|---|---|---|---|---|---|
| 4 | 9 | 20 | 23 | 29 | 30 | 40 | 53 | 1 |
| 5 | 8 | 21 | 22 | 30 | 31 | 36 | 51 | 2 |
| 5 | 11 | 22 | 32 | 41 | 51 | 63 | 94 | 6 |
| 1 | 2 | 7 | 12 | 15 | 20 | 24 | 29 | 10 |
| 1 | 3 | 8 | 14 | 17 | 22 | 25 | 40 | 12 |
- With the table obtained from Step 3, follow the same procedure of Part B (from Step 1) to generate overall K-M curves for the exposed group and the unexposed group and the variance and 95% CI estimators. Note: the table from Step 3 might be irregular with weight-related columns not necessarily decreasing, but this does not affect the computation.
1.12.3 Limitations
The Kaplan-Meier curves cannot be used to verify the proportional hazards assumption because they are not on the log scale. If the survival curves cross between the two exposure groups, the proportional hazards assumption is not met. However, if the survival curves between the two exposure groups do not cross, this does not necessarily mean that the proportional hazards assumption is met. Additionally, 95% CI for K-M curves after variable ratio matching cannot be calculated.
References
Adjusted plots can be returned for matched conditional analyses and weighted analyses; 95% Confidence Intervals will only be included in the title if they are output on the plot↩︎